模拟搜索引擎中文自动分词算法精华(CSFramework特别提供C#源码)
 模拟搜索引擎中文自动分词算法精华(CSFramework特别提供C#源码)
模拟搜索引擎中文自动分词算法精华(CSFramework特别提供C#源码)
什么是中文分词
与大部分印欧语系的语言不同,中文在词与词之间没有任何空格之类的显示标志指示词的边界。因此,中文分词是很多自然语言处理系统中的基础模块和首要环节。
下面示例给读者一个对分词的感性认识:
Text:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
C/S框架网作者基于网友提供的基础源码(KeywordSpliter类)进行深度优化。
优化内容:
1. KeywordSpliter类仅开放一个公共静态方法;方便调用;
2. 修改数处bug;
3. 支持自定义关键词库;
4. 自定义关键词前置,网页的keywords前置关键词便于搜索引擎seo优化和收录。
KeywordSpliter类主要算法逻辑是匹配词库,而不是采用科学的分词方法进行语义智能分析,下面摘抄有关中文分词的方法和评价指标。
从20世纪80年代或更早的时候起,学者们研究了很多的分词方法,这些方法大致可以分为以下几类:
基于词表的分词方法
正向最大匹配法(forward maximum matching method, FMM)
逆向最大匹配法(backward maximum matching method, BMM)
N-最短路径方法
基于统计模型的分词方法
基于N-gram语言模型的分词方法
基于序列标注的分词方法
基于HMM的分词方法
基于CRF的分词方法
基于词感知机的分词方法
基于深度学习的端到端的分词方法
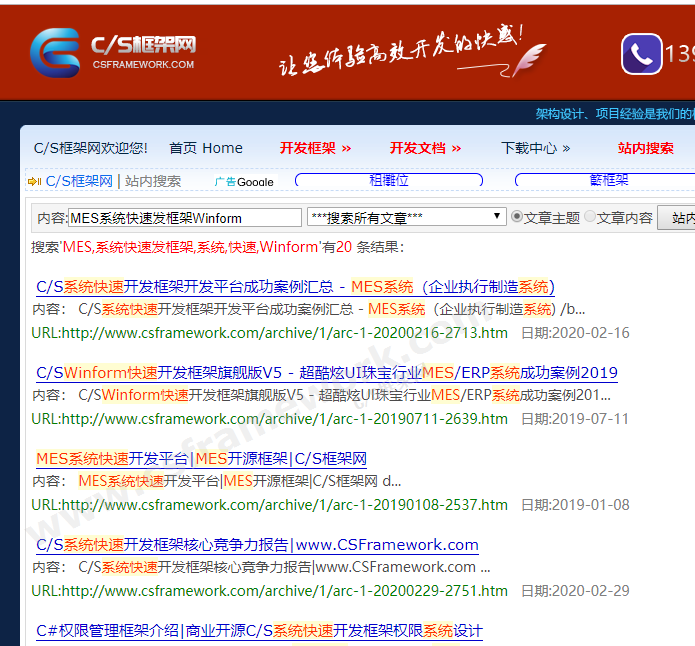
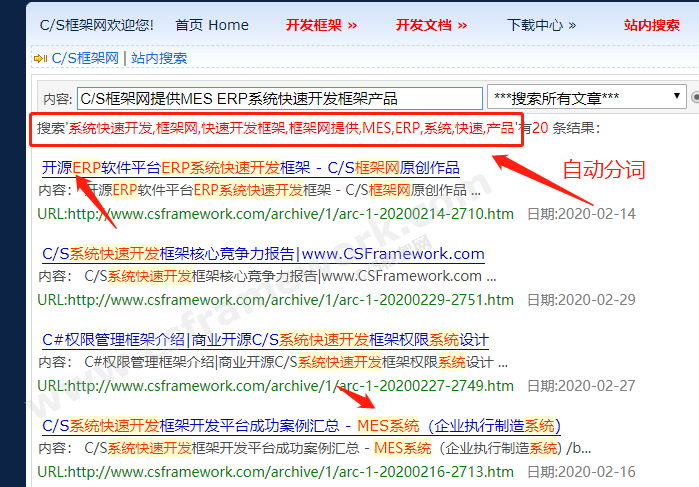
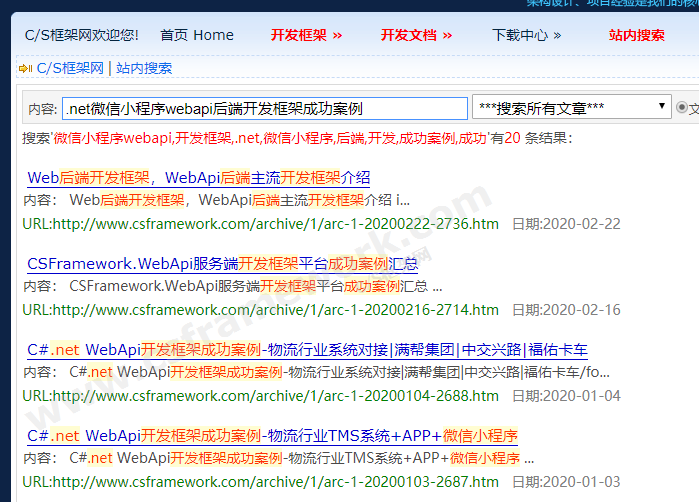
C/S框架网搜索引擎自动分词算法效果:
KeywordSpliter类完整版源码:
C# Code:
/// <summary>
/// C#使用分词算法从文本中抽取关键词|CSFramework.COM优化修订
/// </summary>
public static class KeywordSpliter
{
#region 属性
private static string _SplitChar = " ";//分隔符
//用于移除停止词
private readonly static string[] _StopWordsList = new string[] {"的",
"我们","要","自己","之","将","“","”",",","(",")","后","应","到","某","后",
"个","是","位","新","一","两","在","中","或","有","更","好"
};
#endregion
//加载keywords_default.dic文本文件数据缓存
private static SortedList _KeywordsCacheDefault = null;
//加载keywords_baidu.dic文本文件数据缓存,自定义dic文件(百度关键词,或自定义关键词)
private static SortedList _KeywordsCacheBaidu = null;
/// <summary>
/// 得到分词关键字,以逗号隔开
/// </summary>
/// <param name="keyText"></param>
/// <returns></returns>
public static string DoGetKeyword(string keyText)
{
if (String.IsNullOrEmpty(keyText)) return "";
LoadDict();
LoadDictBaidu();
#region 默认词库分词
StringBuilder sb = new StringBuilder();
ArrayList _key = SplitToList(keyText);
Dictionary<string, int> distinctDict = SortByDuplicateCount(_key);
foreach (KeyValuePair<string, int> pair in distinctDict)
{
sb.Append(pair.Key + ",");
}
#endregion
#region 添加百度关键词,或自定义关键词
//若是单个长词关键词, 添加百度关键词,或自定义关键词
//bool baidu = _KeywordsCacheBaidu.ContainsKey(keyText);
if (!distinctDict.ContainsKey(keyText) && _KeywordsCacheBaidu.ContainsKey(keyText))
{
sb.Insert(0, keyText + ",");//前置关键词,seo较好
}
else //枚举自定义词库
{
string value;
foreach (DictionaryEntry key in _KeywordsCacheBaidu)
{
value = key.Value.ToString();
if (keyText.IndexOf(value) >= 0 && !distinctDict.ContainsKey(value))
sb.Insert(0, value + ",");//前置关键词,seo较好
}
}
#endregion
return sb.ToString();
}
//
#region 读取文本
private static SortedList LoadDictFile(string FilePath)
{
Encoding encoding = Encoding.GetEncoding("utf-8");
SortedList arrText = new SortedList();
//
try
{
if (!File.Exists(FilePath))
{
arrText.Add("0", "文件" + FilePath + "不存在...");
}
else
{
StreamReader objReader = new StreamReader(FilePath, encoding);
string sLine = "";
while (sLine != null)
{
sLine = objReader.ReadLine();
if (!String.IsNullOrEmpty(sLine))
arrText.Add(sLine, sLine);
}
objReader.Close();
objReader.Dispose();
}
}
catch (Exception ex)
{
}
return arrText;
}
#endregion
#region 载入词典
/// <summary>
/// 加载字典文件,并缓存到变量
/// </summary>
private static SortedList LoadDict()
{
string filePath = GetPhysicalFilePath("keywords_default.dic");
if (_KeywordsCacheDefault == null) _KeywordsCacheDefault = LoadDictFile(filePath);
return _KeywordsCacheDefault;
}
private static SortedList LoadDictBaidu()
{
string filePath = GetPhysicalFilePath("keywords_baidu.dic");
if (_KeywordsCacheBaidu == null) _KeywordsCacheBaidu = LoadDictFile(filePath);
return _KeywordsCacheBaidu;
}
/// <summary>
/// 获取物理文件路径
/// </summary>
/// <param name="dictFileName">文件名,如:keywords_baidu.dic</param>
/// <returns></returns>
private static string GetPhysicalFilePath(string dictFileName)
{
//判断是Web服务器环境
if (System.Web.HttpContext.Current != null)
{
string filePath = System.Web.HttpContext.Current.Server.MapPath("~/bin/" + dictFileName);
return filePath;
}
else//其他环境,Winform环境
{
string dir = Path.GetDirectoryName(typeof(KeywordSpliter).Assembly.Location);
string filePath = Path.Combine(dir, dictFileName);
return filePath;
}
}
#endregion
//
#region 正则检测
private static bool IsMatch(string str, string reg)
{
return new Regex(reg).IsMatch(str);
}
#endregion
//
#region 首先格式化字符串(粗分)
private static string FormatStr(string val)
{
string result = "";
if (val == null || val == "")
return "";
//
char[] CharList = val.ToCharArray();
//
string Spc = _SplitChar;//分隔符
int StrLen = CharList.Length;
int CharType = 0; //0-空白 1-英文 2-中文 3-符号
//
for (int i = 0; i < StrLen; i++)
{
string StrList = CharList[i].ToString();
if (StrList == null || StrList == "")
continue;
//
if (CharList[i] < 0x81)
{
#region
if (CharList[i] < 33)
{
if (CharType != 0 && StrList != "\n" && StrList != "\r")
{
result += " ";
CharType = 0;
}
continue;
}
else if (IsMatch(StrList, "[^0-9a-zA-Z@\\.%#:/\\&_-]"))//排除这些字符
{
if (CharType == 0)
result += StrList;
else
result += Spc + StrList;
CharType = 3;
}
else
{
if (CharType == 2 || CharType == 3)
{
result += Spc + StrList;
CharType = 1;
}
else
{
if (IsMatch(StrList, "[@%#:]"))
{
result += StrList;
CharType = 3;
}
else
{
result += StrList;
CharType = 1;
}//end if No.4
}//end if No.3
}//end if No.2
#endregion
}//if No.1
else
{
//如果上一个字符为非中文和非空格,则加一个空格
if (CharType != 0 && CharType != 2)
result += Spc;
//如果是中文标点符号
if (!IsMatch(StrList, "^[\u4e00-\u9fa5]+$"))
{
if (CharType != 0)
result += Spc + StrList;
else
result += StrList;
CharType = 3;
}
else //中文
{
result += StrList;
CharType = 2;
}
}
//end if No.1
}//exit for
//
return result;
}
#endregion
//
#region 分词
/// <summary>
/// 分词
/// </summary>
/// <param name="key">关键词</param>
/// <returns></returns>
private static ArrayList StringSpliter(string[] key)
{
ArrayList List = new ArrayList();
try
{
SortedList dict = LoadDict();//载入词典
//
for (int i = 0; i < key.Length; i++)
{
if (IsMatch(key[i], @"^(?!^\.$)([a-zA-Z0-9\.\u4e00-\u9fa5]+)$")) //中文、英文、数字
{
if (IsMatch(key[i], "^[\u4e00-\u9fa5]+$"))//如果是纯中文
{
int keyLen = key[i].Length;
if (keyLen < 2)
continue;
else if (keyLen <= 7)
List.Add(key[i]);
//
//开始分词
for (int x = 0; x < keyLen; x++)
{
//x:起始位置//y:结束位置
for (int y = x; y < keyLen; y++)
{
string val = key[i].Substring(x, keyLen - y);
if (val == null || val.Length < 2)
break;
else if (val.Length > 10)
continue;
if (dict.Contains(val))
List.Add(val);
}
//
}
//
}
else if (!IsMatch(key[i], @"^(\.*)$"))//不全是小数点
{
List.Add(key[i]);
}
}
}
}
catch (Exception ex)
{
}
return List;
}
#endregion
#region 得到分词结果
/// <summary>
/// 得到分词结果
/// </summary>
/// <param name="keyText"></param>
/// <returns></returns>
private static ArrayList SplitToList(string keyText)
{
ArrayList KeyList = StringSpliter(FormatStr(keyText).Split(_SplitChar.ToCharArray()));
//去掉没用的词
for (int i = 0; i < KeyList.Count; i++)
{
if (IsStopword(KeyList[i].ToString()))
{
KeyList.RemoveAt(i);
}
}
return KeyList;
}
/// <summary>
/// 把一个集合按重复次数排序
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="inputList"></param>
/// <returns></returns>
private static Dictionary<string, int> SortByDuplicateCount(ArrayList inputList)
{
//用于计算每个元素出现的次数,key是元素,value是出现次数
Dictionary<string, int> distinctDict = new Dictionary<string, int>();
for (int i = 0; i < inputList.Count; i++)
{
//这里没用trygetvalue,会计算两次hash
if (distinctDict.ContainsKey(inputList[i].ToString()))
distinctDict[inputList[i].ToString()]++;
else
distinctDict.Add(inputList[i].ToString(), 1);
}
Dictionary<string, int> sortByValueDict = GetSortByValueDict(distinctDict);
return sortByValueDict;
}
/// <summary>
/// 把一个字典value的顺序排序
/// </summary>
/// <typeparam name="K"></typeparam>
/// <typeparam name="V"></typeparam>
/// <param name="distinctDict"></param>
/// <returns></returns>
private static Dictionary<K, V> GetSortByValueDict<K, V>(IDictionary<K, V> distinctDict)
{
//用于给tempDict.Values排序的临时数组
V[] tempSortList = new V[distinctDict.Count];
distinctDict.Values.CopyTo(tempSortList, 0);
Array.Sort(tempSortList); //给数据排序
Array.Reverse(tempSortList);//反转
//用于保存按value排序的字典
Dictionary<K, V> sortByValueDict =
new Dictionary<K, V>(distinctDict.Count);
for (int i = 0; i < tempSortList.Length; i++)
{
foreach (KeyValuePair<K, V> pair in distinctDict)
{
//比较两个泛型是否相当要用Equals,不能用==操作符
if (pair.Value.Equals(tempSortList[i]) && !sortByValueDict.ContainsKey(pair.Key))
sortByValueDict.Add(pair.Key, pair.Value);
}
}
return sortByValueDict;
}
#endregion
private static bool IsStopword(string str)
{
return _StopWordsList.Contains(str);
}
}
//来源:C/S框架网(www.csframework.com) QQ:23404761
/// C#使用分词算法从文本中抽取关键词|CSFramework.COM优化修订
/// </summary>
public static class KeywordSpliter
{
#region 属性
private static string _SplitChar = " ";//分隔符
//用于移除停止词
private readonly static string[] _StopWordsList = new string[] {"的",
"我们","要","自己","之","将","“","”",",","(",")","后","应","到","某","后",
"个","是","位","新","一","两","在","中","或","有","更","好"
};
#endregion
//加载keywords_default.dic文本文件数据缓存
private static SortedList _KeywordsCacheDefault = null;
//加载keywords_baidu.dic文本文件数据缓存,自定义dic文件(百度关键词,或自定义关键词)
private static SortedList _KeywordsCacheBaidu = null;
/// <summary>
/// 得到分词关键字,以逗号隔开
/// </summary>
/// <param name="keyText"></param>
/// <returns></returns>
public static string DoGetKeyword(string keyText)
{
if (String.IsNullOrEmpty(keyText)) return "";
LoadDict();
LoadDictBaidu();
#region 默认词库分词
StringBuilder sb = new StringBuilder();
ArrayList _key = SplitToList(keyText);
Dictionary<string, int> distinctDict = SortByDuplicateCount(_key);
foreach (KeyValuePair<string, int> pair in distinctDict)
{
sb.Append(pair.Key + ",");
}
#endregion
#region 添加百度关键词,或自定义关键词
//若是单个长词关键词, 添加百度关键词,或自定义关键词
//bool baidu = _KeywordsCacheBaidu.ContainsKey(keyText);
if (!distinctDict.ContainsKey(keyText) && _KeywordsCacheBaidu.ContainsKey(keyText))
{
sb.Insert(0, keyText + ",");//前置关键词,seo较好
}
else //枚举自定义词库
{
string value;
foreach (DictionaryEntry key in _KeywordsCacheBaidu)
{
value = key.Value.ToString();
if (keyText.IndexOf(value) >= 0 && !distinctDict.ContainsKey(value))
sb.Insert(0, value + ",");//前置关键词,seo较好
}
}
#endregion
return sb.ToString();
}
//
#region 读取文本
private static SortedList LoadDictFile(string FilePath)
{
Encoding encoding = Encoding.GetEncoding("utf-8");
SortedList arrText = new SortedList();
//
try
{
if (!File.Exists(FilePath))
{
arrText.Add("0", "文件" + FilePath + "不存在...");
}
else
{
StreamReader objReader = new StreamReader(FilePath, encoding);
string sLine = "";
while (sLine != null)
{
sLine = objReader.ReadLine();
if (!String.IsNullOrEmpty(sLine))
arrText.Add(sLine, sLine);
}
objReader.Close();
objReader.Dispose();
}
}
catch (Exception ex)
{
}
return arrText;
}
#endregion
#region 载入词典
/// <summary>
/// 加载字典文件,并缓存到变量
/// </summary>
private static SortedList LoadDict()
{
string filePath = GetPhysicalFilePath("keywords_default.dic");
if (_KeywordsCacheDefault == null) _KeywordsCacheDefault = LoadDictFile(filePath);
return _KeywordsCacheDefault;
}
private static SortedList LoadDictBaidu()
{
string filePath = GetPhysicalFilePath("keywords_baidu.dic");
if (_KeywordsCacheBaidu == null) _KeywordsCacheBaidu = LoadDictFile(filePath);
return _KeywordsCacheBaidu;
}
/// <summary>
/// 获取物理文件路径
/// </summary>
/// <param name="dictFileName">文件名,如:keywords_baidu.dic</param>
/// <returns></returns>
private static string GetPhysicalFilePath(string dictFileName)
{
//判断是Web服务器环境
if (System.Web.HttpContext.Current != null)
{
string filePath = System.Web.HttpContext.Current.Server.MapPath("~/bin/" + dictFileName);
return filePath;
}
else//其他环境,Winform环境
{
string dir = Path.GetDirectoryName(typeof(KeywordSpliter).Assembly.Location);
string filePath = Path.Combine(dir, dictFileName);
return filePath;
}
}
#endregion
//
#region 正则检测
private static bool IsMatch(string str, string reg)
{
return new Regex(reg).IsMatch(str);
}
#endregion
//
#region 首先格式化字符串(粗分)
private static string FormatStr(string val)
{
string result = "";
if (val == null || val == "")
return "";
//
char[] CharList = val.ToCharArray();
//
string Spc = _SplitChar;//分隔符
int StrLen = CharList.Length;
int CharType = 0; //0-空白 1-英文 2-中文 3-符号
//
for (int i = 0; i < StrLen; i++)
{
string StrList = CharList[i].ToString();
if (StrList == null || StrList == "")
continue;
//
if (CharList[i] < 0x81)
{
#region
if (CharList[i] < 33)
{
if (CharType != 0 && StrList != "\n" && StrList != "\r")
{
result += " ";
CharType = 0;
}
continue;
}
else if (IsMatch(StrList, "[^0-9a-zA-Z@\\.%#:/\\&_-]"))//排除这些字符
{
if (CharType == 0)
result += StrList;
else
result += Spc + StrList;
CharType = 3;
}
else
{
if (CharType == 2 || CharType == 3)
{
result += Spc + StrList;
CharType = 1;
}
else
{
if (IsMatch(StrList, "[@%#:]"))
{
result += StrList;
CharType = 3;
}
else
{
result += StrList;
CharType = 1;
}//end if No.4
}//end if No.3
}//end if No.2
#endregion
}//if No.1
else
{
//如果上一个字符为非中文和非空格,则加一个空格
if (CharType != 0 && CharType != 2)
result += Spc;
//如果是中文标点符号
if (!IsMatch(StrList, "^[\u4e00-\u9fa5]+$"))
{
if (CharType != 0)
result += Spc + StrList;
else
result += StrList;
CharType = 3;
}
else //中文
{
result += StrList;
CharType = 2;
}
}
//end if No.1
}//exit for
//
return result;
}
#endregion
//
#region 分词
/// <summary>
/// 分词
/// </summary>
/// <param name="key">关键词</param>
/// <returns></returns>
private static ArrayList StringSpliter(string[] key)
{
ArrayList List = new ArrayList();
try
{
SortedList dict = LoadDict();//载入词典
//
for (int i = 0; i < key.Length; i++)
{
if (IsMatch(key[i], @"^(?!^\.$)([a-zA-Z0-9\.\u4e00-\u9fa5]+)$")) //中文、英文、数字
{
if (IsMatch(key[i], "^[\u4e00-\u9fa5]+$"))//如果是纯中文
{
int keyLen = key[i].Length;
if (keyLen < 2)
continue;
else if (keyLen <= 7)
List.Add(key[i]);
//
//开始分词
for (int x = 0; x < keyLen; x++)
{
//x:起始位置//y:结束位置
for (int y = x; y < keyLen; y++)
{
string val = key[i].Substring(x, keyLen - y);
if (val == null || val.Length < 2)
break;
else if (val.Length > 10)
continue;
if (dict.Contains(val))
List.Add(val);
}
//
}
//
}
else if (!IsMatch(key[i], @"^(\.*)$"))//不全是小数点
{
List.Add(key[i]);
}
}
}
}
catch (Exception ex)
{
}
return List;
}
#endregion
#region 得到分词结果
/// <summary>
/// 得到分词结果
/// </summary>
/// <param name="keyText"></param>
/// <returns></returns>
private static ArrayList SplitToList(string keyText)
{
ArrayList KeyList = StringSpliter(FormatStr(keyText).Split(_SplitChar.ToCharArray()));
//去掉没用的词
for (int i = 0; i < KeyList.Count; i++)
{
if (IsStopword(KeyList[i].ToString()))
{
KeyList.RemoveAt(i);
}
}
return KeyList;
}
/// <summary>
/// 把一个集合按重复次数排序
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="inputList"></param>
/// <returns></returns>
private static Dictionary<string, int> SortByDuplicateCount(ArrayList inputList)
{
//用于计算每个元素出现的次数,key是元素,value是出现次数
Dictionary<string, int> distinctDict = new Dictionary<string, int>();
for (int i = 0; i < inputList.Count; i++)
{
//这里没用trygetvalue,会计算两次hash
if (distinctDict.ContainsKey(inputList[i].ToString()))
distinctDict[inputList[i].ToString()]++;
else
distinctDict.Add(inputList[i].ToString(), 1);
}
Dictionary<string, int> sortByValueDict = GetSortByValueDict(distinctDict);
return sortByValueDict;
}
/// <summary>
/// 把一个字典value的顺序排序
/// </summary>
/// <typeparam name="K"></typeparam>
/// <typeparam name="V"></typeparam>
/// <param name="distinctDict"></param>
/// <returns></returns>
private static Dictionary<K, V> GetSortByValueDict<K, V>(IDictionary<K, V> distinctDict)
{
//用于给tempDict.Values排序的临时数组
V[] tempSortList = new V[distinctDict.Count];
distinctDict.Values.CopyTo(tempSortList, 0);
Array.Sort(tempSortList); //给数据排序
Array.Reverse(tempSortList);//反转
//用于保存按value排序的字典
Dictionary<K, V> sortByValueDict =
new Dictionary<K, V>(distinctDict.Count);
for (int i = 0; i < tempSortList.Length; i++)
{
foreach (KeyValuePair<K, V> pair in distinctDict)
{
//比较两个泛型是否相当要用Equals,不能用==操作符
if (pair.Value.Equals(tempSortList[i]) && !sortByValueDict.ContainsKey(pair.Key))
sortByValueDict.Add(pair.Key, pair.Value);
}
}
return sortByValueDict;
}
#endregion
private static bool IsStopword(string str)
{
return _StopWordsList.Contains(str);
}
}
//来源:C/S框架网(www.csframework.com) QQ:23404761
测试案例:
C# Code:
class Program
{
static void Main(string[] args)
{
//测试案例
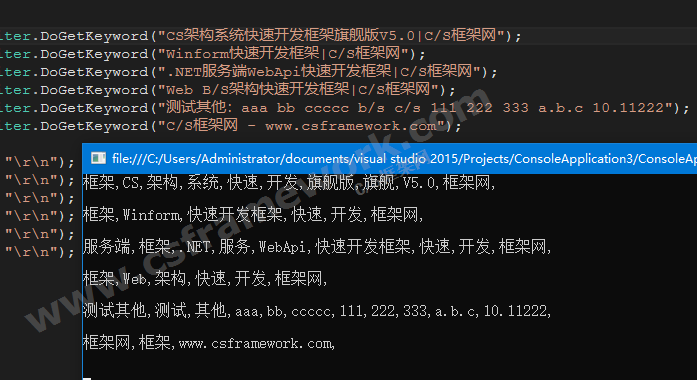
string s0 = KeywordSpliter.DoGetKeyword("CS架构系统快速开发框架旗舰版V5.0|C/S框架网");
string s1 = KeywordSpliter.DoGetKeyword("Winform快速开发框架|C/S框架网");
string s2 = KeywordSpliter.DoGetKeyword(".NET服务端WebApi快速开发框架|C/S框架网");
string s3 = KeywordSpliter.DoGetKeyword("Web B/S架构快速开发框架|C/S框架网");
string s4 = KeywordSpliter.DoGetKeyword("测试其他:aaa bb ccccc b/s c/s 111 222 333 a.b.c 10.11222");
string s5 = KeywordSpliter.DoGetKeyword("C/S框架网 - www.csframework.com");
Console.WriteLine(s0 + "\r\n");
Console.WriteLine(s1 + "\r\n");
Console.WriteLine(s2 + "\r\n");
Console.WriteLine(s3 + "\r\n");
Console.WriteLine(s4 + "\r\n");
Console.WriteLine(s5 + "\r\n");
Console.ReadKey();
}
}
//来源:C/S框架网(www.csframework.com) QQ:23404761
{
static void Main(string[] args)
{
//测试案例
string s0 = KeywordSpliter.DoGetKeyword("CS架构系统快速开发框架旗舰版V5.0|C/S框架网");
string s1 = KeywordSpliter.DoGetKeyword("Winform快速开发框架|C/S框架网");
string s2 = KeywordSpliter.DoGetKeyword(".NET服务端WebApi快速开发框架|C/S框架网");
string s3 = KeywordSpliter.DoGetKeyword("Web B/S架构快速开发框架|C/S框架网");
string s4 = KeywordSpliter.DoGetKeyword("测试其他:aaa bb ccccc b/s c/s 111 222 333 a.b.c 10.11222");
string s5 = KeywordSpliter.DoGetKeyword("C/S框架网 - www.csframework.com");
Console.WriteLine(s0 + "\r\n");
Console.WriteLine(s1 + "\r\n");
Console.WriteLine(s2 + "\r\n");
Console.WriteLine(s3 + "\r\n");
Console.WriteLine(s4 + "\r\n");
Console.WriteLine(s5 + "\r\n");
Console.ReadKey();
}
}
//来源:C/S框架网(www.csframework.com) QQ:23404761
Console程序测试结果:
扫一扫加微信:


版权声明:本文为开发框架文库发布内容,转载请附上原文出处连接
NewDoc C/S框架网