使用HtmlAgilityPack.HtmlDocument彻底清除HTML标签

测试案例1
HTML原文地址:https://www.csframework.com/archive/1/arc-1-20211205-4041.htm
去除HTML标签后:
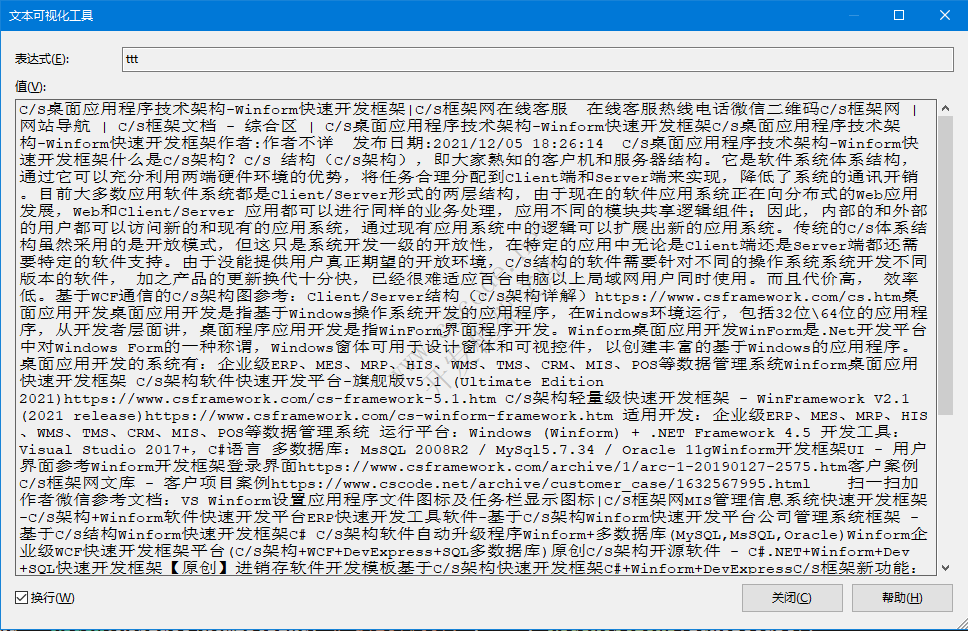
测试案例2
原文地址:https://www.cnblogs.com/Yellowshorts/archive/2013/03/09/2951503.html
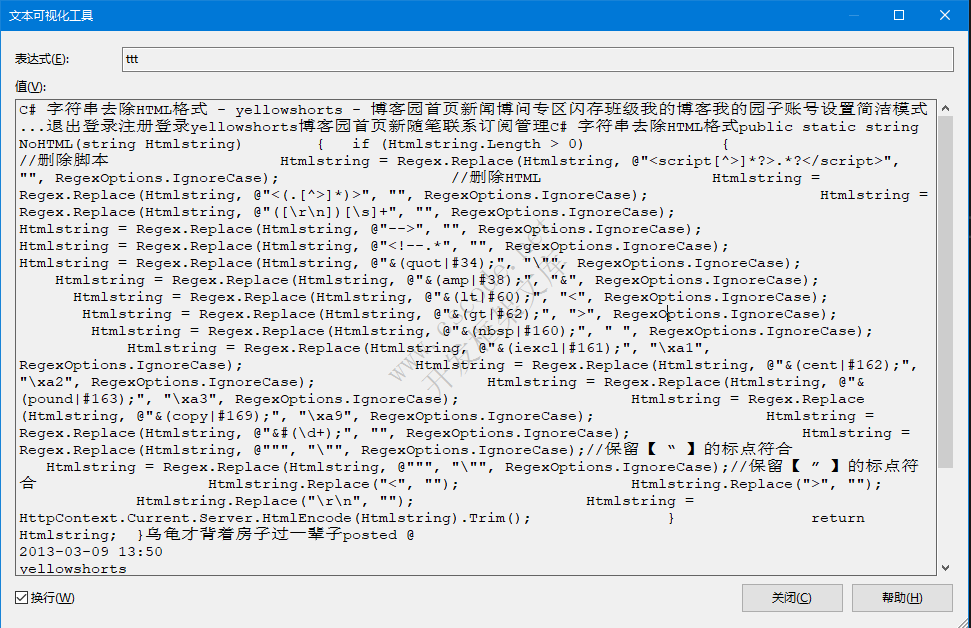
去除HTML标签后:
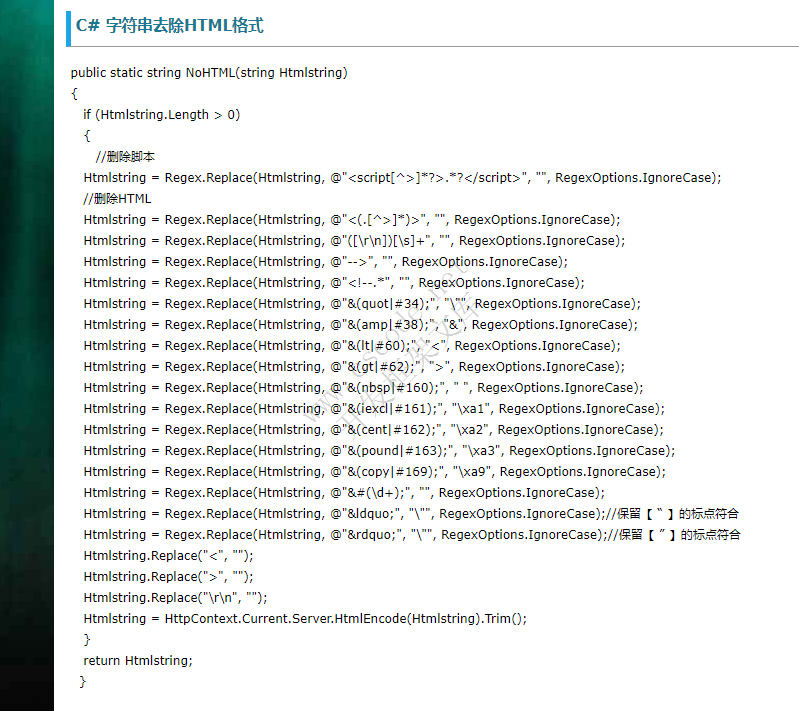
C#源码
C# 全选
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
namespace CSFramework.HtmlSpider
{
public class SpiderTool
{
/// <summary>
/// 移除HTML
/// </summary>
/// <param name="htmlContent"></param>
/// <returns></returns>
public static string RemoveHTML(string htmlContent)
{
//移除HTML
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(htmlContent);
var ttt = doc.DocumentNode.InnerText.Trim();//清除HTML标签
ttt = RemoveEmptyLine(ttt);
ttt = RemoveHtmlTags(ttt);
return ttt;
}
public static string RemoveHtmlTags(string Htmlstring)
{
if (Htmlstring.Length > 0)
{
//删除脚本
Htmlstring = Regex.Replace(Htmlstring, @"<script[^>]*?>.*?</script>", "", RegexOptions.IgnoreCase);
//删除HTML
Htmlstring = Regex.Replace(Htmlstring, @"<(.[^>]*)>", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"([\r\n])[\s]+", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"-->", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"<!--.*", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(quot|#34);", "\"", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(amp|#38);", "&", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(lt|#60);", "<", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(gt|#62);", ">", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(nbsp|#160);", " ", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(iexcl|#161);", "\xa1", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(cent|#162);", "\xa2", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(pound|#163);", "\xa3", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&(copy|#169);", "\xa9", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"&#(\d+);", "", RegexOptions.IgnoreCase);
Htmlstring = Regex.Replace(Htmlstring, @"“", "\"", RegexOptions.IgnoreCase);//保留【 “ 】的标点符合
Htmlstring = Regex.Replace(Htmlstring, @"”", "\"", RegexOptions.IgnoreCase);//保留【 ” 】的标点符合
Htmlstring.Replace("<", "");
Htmlstring.Replace(">", "");
Htmlstring.Replace("\r\n", "");
}
return Htmlstring;
}
/// <summary>
/// 去掉空行
/// </summary>
/// <param name="content"></param>
/// <returns></returns>
public static string RemoveEmptyLine(string content)
{
StringBuilder sb = new StringBuilder();
string[] lines = content.Split(new string[] { "\r\n" }, StringSplitOptions.RemoveEmptyEntries);
string tmp;
foreach (string s in lines)
{
tmp = s.Trim();
if (String.IsNullOrEmpty(tmp) || String.IsNullOrWhiteSpace(tmp))
continue;
else
sb.AppendLine(tmp);
}
return sb.ToString();
}
}
}
版权声明:本文为开发框架文库发布内容,转载请附上原文出处连接
NewDoc C/S框架网