百度搜索引擎Robots.txt文件参数详解

Robots.txt 文件
Robots是站点与spider沟通的重要渠道,站点通过robots文件声明本网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。
搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中声明 该网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。
请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。但robots.txt不是命令,也不是防火墙,如同守门人无法阻止窃贼等恶意闯入者。
Robots 使用说明
1. robots.txt可以告诉百度您网站的哪些页面可以被抓取,哪些页面不可以被抓取。
2. 您可以通过Robots工具来创建、校验、更新您的robots.txt文件,或查看您网站robots.txt文件在百度生效的情况。
3. Robots工具目前支持48k的文件内容检测,请保证您的robots.txt文件不要过大,目录最长不超过250个字符。
Robots 参数
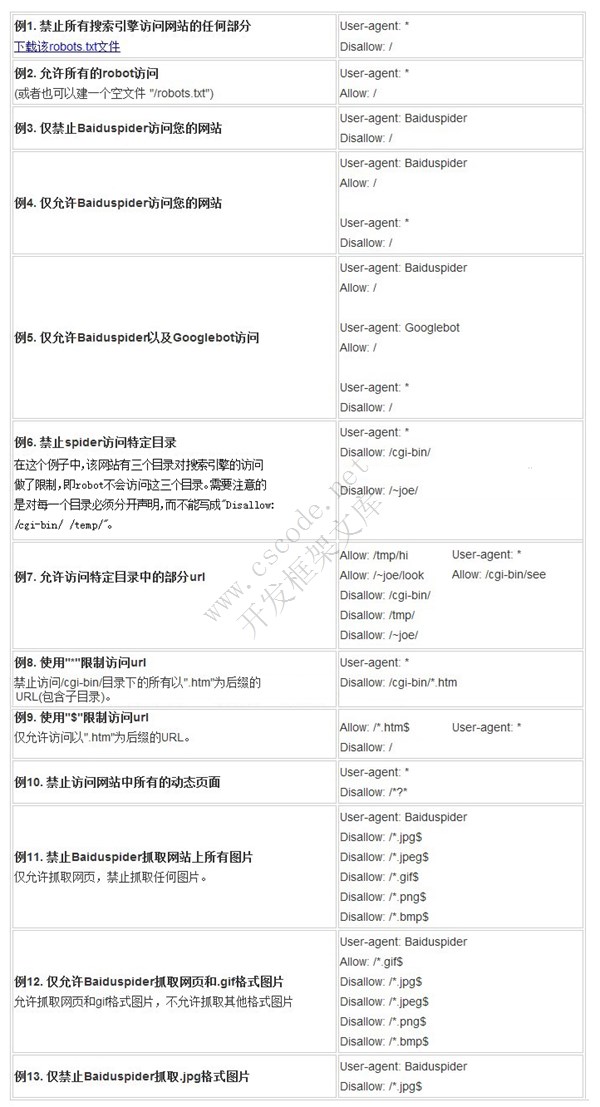
User-agent: * 这里的代表的所有的搜索引擎种类,是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow: /? 禁止访问网站中所有的动态页面
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Robots 全部参数,来自百度站长
检测并更新Robots文件
当修改了robots.txt文件,要检测并更新Robots